When ‚computer vision’ or ‚machine vision’ became possible in the last half of the twentieth century due to the advent of powerful digital (micro-) processors, several avenues to its development opened up. The starting point was processing of single digital images for exploration of unknown or not sufficiently well known spaces like the surfaces of the moon or other planets, inaccessible environments in agriculture, geodesy or battle field territory.
With computing power developing at a rate of about one order of magnitude every four to five years since the advent of the microprocessor in the early 1970s, application areas rapidly spread to a wide range; the following figure shows types of vision systems with those components marked by bold letters that were selected as starting point for dynamic vision in the 1980s:
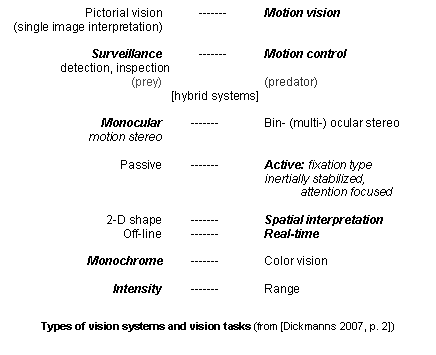
The usual approach to computer vision with the limited computing power available in the early 1980s (typical: clock rate of a few MHz, 8- and 16-bit microprocessors), was to start developing feature extraction and image interpretation from single snapshots or a small sequence of images stored in memory. Simple evaluation of a single small image needed several seconds to minutes. The hope was that with the development of computing power this time would shrink to tens of milliseconds (needed speed-up of ~ 3 orders of magnitude, i.e. ~ 1½ decades). Big development projects were started like DARPA’s ‘On Strategic Computing’ to investigate new computer architectures with massively parallel processors [Klass 1985; Kuan et al. 1986; Thorpe et al. 1987; Scudder and Weems 1990; Hillis 1992; Roland and Shiman 2002]. Spatial interpretation had to be done by inversion of perspective projection of images taken from different viewpoints (sets of two or more cameras). Intermediate interpretation steps like ‘2.5-D vision’ were chosen as a common approach [Waltz 1975; Marr 1982].
Fundamentally in contrast to this generally accepted procedure needing storage of image sequences for real-time vision, ‘dynamic vision’ started from recursive estimation algorithms [Kalman 1960; Luenberger 1964] with spatiotemporal models for motion processes of objects to be observed [Dickmanns 1987]; perspective projection was considered just a nonlinear measurement process with some process states not directly accessible (like depth or range). Since 3-D space was an integral part of the model together with constraints to temporal changes (time as fourth dimension), the approach was dubbed ‘4-D approach’ to real-time vision. One big advantage right from the beginning was that no previous images needed be stored, even for stereo interpretation (motion stereo).
State of recursive estimation in the AI- and Computer Science community (1987)
At that time, Kalman filtering had acquired a bad reputation for image sequence evaluation. The temporal continuity models typically applied were formulated in the image plane (2-D) and not for the physical world where they really hold; feature speed was assumed constant in each direction in the image, usually, and for adaptation a noise term was added. The nonlinear perspective mapping conditions were locally approximated, and the entries in the Jacobian matrices were selected as some reasonably looking constants. The convergence process was claimed to be brittle and not robust. Disappearance of features was dubbed a ‘catastrophic event’ and not considered as a normal event in a more complex situation with self-occlusion by rotation of the body or by motion behind another object. So the performance achieved by our group in the early 1980s with realistic physical models including full perspective mapping (pinhole camera) as nonlinear measurement model in a real-time process came as a surprise.
The 4-D approach to dynamic vision
Space with three orthogonal components and time are the four dimensions (4-D) for motion in six degrees of freedom (dof); this is the sufficiently general formulation for our everyday (meso-scale) world. [Only in both galactic and nano-scale spaces (processes) higher dimensions have shown advantages in modeling.] − In order to have the entire team think in terms of real-time process observation, a lower limit for image interpretation frequency has been set to about 10 Hz right from the beginning (0.1 second for each frame in a sequence analyzed). The vision tasks had to be selected correspondingly, but it soon turned out that the short time intervals available allowed developing a different look at visual perception and process control:
- Nonlinear processes could easily be approximated by simple, locally valid, linear models, the parameters of which may be adapted after each measurement step.
- Search ranges for features found last time could be kept small; since the image plane is 2-D, this may cut down feature re-detection time considerably (square effect).
- Second order dynamic models (‘Newton’s laws’) allow integrated speed estimation in parallel to position estimation, which in turn alleviates realistic computation of expectations according to the model chosen.
- Motion models for different degrees of freedom may initially be selected independent of each other to reduce complexity (e.g. a second order Newton equation along and around each coordinate axis); however, if the motion elements are not independent in reality (like rotation around the vertical axis for ground vehicles with ‘Ackermann-steering’ in normal driving) the corresponding (non-holonomic) constraints can be included in the interpretation process very simply and readily.
- Knowledge about motion processes of objects is specific to task domains; this allows grouping of knowledge elements needed both for perception and for control to make closed loop behavior efficient.
Applications to ground-, air- and space vehicles have been developed at UniBwM over the last quarter of the 20th century. The following visualization of the 4-D approach has emerged over the years

In the meantime, using recursive estimation with sufficiently correct dynamic (physical) models and perspective mapping has become standard and commonplace around the world in real-time vision; the term ‘4-D approach’ is rarely used though the approaches follow the same ideas, essentially. In a stationary environment, where all objects observed except the vehicle carrying the camera remain in fix positions and orientations over time, the general problem reduces to the task domain in the field of geodesy well known under the label ‘photogrammetry’: Given several snapshots of an environment, what are the locations of objects seen in the images, and what are the locations from which the snapshots were taken. For image sequences taken with a camera on a moving vehicle (or carried by a person), some constraints on (vehicle) motion may be exploited in addition; for this field a new name was coined in the early 1990’s:
SLAM and 6D – SLAM: In the early 1990s, the label ‘Simultaneous Localization And Mapping’ (short SLAM) was propagated [Leonard and Durrant-Whyte 1991] for a specialized set of tasks [Ayache and Faugeras 1989]. It addresses the long existing challenge in the field of photogrammetry: Given a sequence of images from a static environment, determine the relative location of the camera and of objects in the images.
Initially, only translational variables and one angle around the vertical axis for (the vehicle carrying) the camera have been used; motion models for camera movements were predominantly kinematic [Guivant and Nebot 2001; Montemerlo 2003; Haehnel et al. 2003; Nieto et al. 2003]. For the objects observed, range and bearing (or corresponding Cartesian coordinates) have been introduced as state variables to be iterated. Changes of aspect conditions on visual appearance have been neglected initially.
Later on, when object orientation around up to three axes or velocity components were taken into account additionally, the term “6-D SLAM” has been proposed and widely accepted [Nuechter et al. 2004; Nuechter et al. 2006]; the capital letter “D” is not to be confused with ‘Dimension’ (as in 4-D) but stands for ‘Degrees-of-freedom’ (in engineering terms generally dubbed ‘dof’). But also in 6D-SLAM mechanical motion is not modelled as a second-order process with position and speed components as state variables (according to Newton’s laws). The model is correct for stationary objects only (speed = zero); as soon as moving objects are also perceived in the same framework, knowledge about the physical world is not fully exploited. If physically correct models are chosen both for the translational and the rotational degrees of freedom, the original 4-D approach from 1987 is obtained with 12 state variables for one rigid body.
Advantages of the 4-D approach
The essential aspect by introducing Newton’s (second order) motion laws as temporal constraints in the recursive interpretation process is that speed components are state variables that can be reconstructed from observing image sequences; however, in this approach at one point in time one has to deal with the last image of the sequence only. In addition, simultaneously the notion of speed components and their relation to control inputs is represented through the dynamic models (if these are physically correct!).
When both the body carrying the camera and other objects observed through images are moving, inertial sensing of linear accelerations and rotation rates of the own body allows separating eigenmotion from object motion. Together with recursive visual estimation of motion of objects relative to the projection center of the camera one can arrive at reasonable estimates for the absolute motion of objects. However, since egostate estimation by integration of inertial signals over extended periods of time tends to generate drift errors caused by sensor noise, stabilization by vision would be most welcome. If stationary objects can be recognized in the image sequence, they allow this low-frequency stabilization for which the delay time in image understanding (usually 100 milliseconds or more, i.e. several video cycles) is much less serious than for full state estimation at video rate.
In addition, inertial signals contain the acceleration effects of perturbations on the body immediately, while in vision the effects of perturbations show up with relatively large delays. The reason is that perspective mapping is based on position as the second integral of accelerations. – Nature has developed and implemented this principle in vertebrate vision for millions of years.
There is a second beneficial effect to sensing of rotation rates: If these signals measured right at the location of the vision sensor are used to control gaze direction by negative feedback, the angular perturbations on the vision sensors can be reduced by more than an order of magnitude [Schiehlen 1995; 2007 Dickmanns, page 382].
Figure VaMoRs Breaking Gaze Stabilization
Note that the effects of position changes of a camera (translational states) are much less pronounced in an image for objects further away (needed for angular stabilization); therefore, usually the acceleration signals are taken only for speed estimation and for improving relative state estimation to objects nearby.
Once gaze control is available in the vision system, it can also be used to lock gaze onto a moving object by direct feedback of visual features. This allows reducing motion blur for this object (though inducing more blur for other objects moving in opposite direction); in a well-developed vision system this leads to active attention control depending on the situation encountered. In this case, multi-focal vision systems with different focal lengths simultaneously in operation are of advantage. The internal representation of speed components for all objects of interest can improve attention control by short-term predictions and longer-term expectations based on typical motion behavior for objects of certain classes.
All these aspects together have led to the development of “Expectation-based, Multi-focal, Saccadic (EMS) vision” with a “Multi-focal active/reactive Vehicle Eye” (MarVEye) [Dickmanns 2007, page 392; Dickmanns 2015, Part III]:
A fork in the development of dynamic vision systems (~ 2004)
After ‘Expectation-based, Multi-focal, Saccadic (EMS)’ vision had been developed in the joint German – US American project ‘AutoNav’ (1997 – 2001), the American partners succeeded in convincing the US-congress that further funding in the USA should be enhanced by making a statement in the Defense-budget; it says that by 2015 about one third of new ground vehicles for combat should have the capability of performing part of their missions by autonomous driving. This was the entry point for DARPA to formulate its ‘Grand Challenge’ (2004/05) and Urban Challenge (2007) with large sums in price money for the winner.
However, in order to attract more competitors for the Challenge, DARPA specified supply missions in well-known and -prepared environments as goal. In these applications the trajectory to be driven was specified by a dense net of GPS-waypoints, and the vehicles had the task of avoiding obstacles above the driving plane, not necessarily by vision. 360°-revolving laser-range-finders funded in previous years by DARPA were the main optical sensors used. Some of the many groups participating did not even have cameras on board.
Note that this task is quite different from the one treated by EMS-vision. There, the autonomous vehicle has to find its safe route in unknown terrain without previous detailed knowledge from precise maps. Therefore, this type of vision is now called ‘scout-type’ [Dickmanns 2017; end of section 4]. On the contrary, the line of development based on precise and recent knowledge about the environment to be driven is dubbed ‘confirmation-type’ vision in this article. Its application relies on well-known environmental data of recent origin. This may be made available in the future for densely populated areas with frequent traffic. However, for large rural areas and for remote regions this branch of vision may not be applicable because of the high recurring costs. After recent disasters (heavy snow and storm damages etc.) only scout-type vision may be practically relevant.
Most vision systems developed presently by industry for application in autonomous driving on (generally smooth) roads rely on confirmation-type vision; this needs fewer capabilities for perception and understanding since dealing with well-known environments. For driving on rugged surfaces and in unknown terrain, scout-type vision with multifocal, inertially-stabilized cameras will be required if human performance levels in perception are to be achieved.
References (in temporal order)
Kalman RD (1960). A new approach to linear filtering and prediction problems. Trans. ASME, Series D, Journal of Basic Engineering: 35 – 45.
Luenberger DG (1964). Observing the state of a linear system. IEEE Trans. on Military Electronics 8: 74-80; 290-293.
Waltz D (1975). Understanding line drawings of scenes with shadows. In: The Psychology of Computer Vision, Winston, PH (ed), McGraw-Hill, New York, 19 – 91.
Marr D (1982). Vision. Freeman,
Meissner HG, Dickmanns ED (1983). Control of an Unstable Plant by Computer Vision. In T.S. Huang (ed): Image Sequence Processing and Dynamic Scene Analysis. Springer-Verlag, Berlin, pp 532-548
Klass P.J. (1985): DARPA Envisions New Generation of Machine Intelligence. Aviation Week & Space Technology, April: 47–54
Kuan D., Phipps G., Hsueh A.C. (1986): A real time road following vision system for autonomous vehicles. Proc. SPIE Mobile Robots Conf., 727, Cambridge MA: 152–160
Thorpe C., Hebert M., Kanade T., Shafer S. (1987): Vision and navigation for the CMU Navlab. Annual Review of Computer Science, Vol. 2
Dickmanns ED (1987). 4-D Dynamic Scene Analysis with Integral Spatio-Temporal Models. 4th Int. Symposium on Robotics Research, Santa Cruz. In: Bolles RC, Roth B (1988). Robotics Research, MIT Press, Cambridge, pp 311-318 pdf
Smith R, Self M, Cheeseman P (1987). A stochastic map for uncertain spatial relationships. Autonomous Mobile Robots : Perception, Mapping and Navigation, 1, pp 323-330.
Ayache N, Faugeras O (1989). Maintaining a representation of the environment of a mobile robot. IEEE Transactions on Robotics and Automation, 5(6), pp 804-819.
Scudder M., Weems C.C. (1990): An Apply Compiler for the CAAPP. Tech. Rep. UM-CS-1990-060, University of Massachusetts, Amherst
Leonard JJ, Durrant-Whyte HF (1991). Simultaneous map building and localization for an autonomous mobile robot. In: Proceedings of the IEEE Int. Workshop on Intelligent Robots and Systems, Osaka, Japan, pp 1442–1447,
Hillis W.D. (1992) (6th printing): The Connection Machine. MIT Press, Cambridge, MA
Schiehlen J (1995). Kameraplattformen für aktiv sehende Fahrzeuge. Dissertation, UniBwM / LRT. Also as Fortschritts-berichte VDI Verlag, Reihe 8, Nr. 514. Kurzfassung
Guivant J, Nebot E (2001). Optimization of the simultaneous localization and map building algorithm for real-time implementation. IEEE Transactions on Robotics and Automation, 17, pp 41-76.
Roland A., Shiman P. (2002): Strategic Computing: DARPA and the Quest for Machine Intelligence, 1983–1993. MIT Press
Montemerlo M (2003). FastSLAM: A Factored Solution to the Simultaneous Localization and Mapping Problem with Unknown Data Association. PhD thesis, Robotics Institute, Carnegie Mellon University, Pittsburgh.
Nieto J, Guivant J, Nebot E, Thrun S (2003). Real time data association for Fast-SLAM. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA).
Haehnel D, Fox D, Burgard W, Thrun S (2003). A highly efficient FastSLAM algorithm for generating cyclic maps of large-scale environments from raw laser range measurements. In Proc. of the Conference on Intelligent Robots and Systems (IROS).
Nuechter A, Surmann H, Lingemann K, Hertzberg J, Thrun S (2004). 6D SLAM with an Application in Autonomous Mine Mapping. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA ’04), pages 1998 – 2003, New Orleans, USA
Nüchter A, Lingemann K, Hertzberg J (2006). Extracting Drivable Surfaces in Outdoor 6D SLAM. In Proceedings of the 37th International Symposium on Robotics (ISR ’06) and Robotik 2006, Munich
Dickmanns ED (2007) Dynamic Vision for Perception and Control of Motion. Springer-Verlag, London (474 pages, Content)
Dickmanns ED (2017) Entwicklung des Gesichtssinns für autonomes Fahren – Der 4-D Ansatz brachte 1987 den Durchbruch. In VDI-Berichte 2292: AUTOREG 2017, VDI Verlag GmbH (ISBN 978-3-18-092233-1 (S. 5-20) pdf